人工智能之自然语言处理初探

最近在梳理人工智能的一个细分领域自然语言处理相关知识点。随着查阅的资料越来越多,在梳理的过程中,也越来越发现自己的无知。虽然自然语言处理是人工智能的一个细分领域,但是自然语言处理这个细分领域内,又有很多的细分领域。自然语言处理,也是涵盖了多个学科的一个系统化的大型工程。自然语言处理,除了包含常见的分词、分句、分段,词目计算、词类标注,有限状态自动机、隐马尔可夫模型等基础的计算机理论知识外,还包含了语音学、语言学、心理学、统计学、脑科学等多个领域的学科知识。一个人不可能把自然语言处理所有的知识都全部掌握精通,也只能是找到其中的一个或几个难点进行研究。今天文章题目定为《人工智能之自然语言处理初探》,似乎题目也是有点过大了。所以又取了一个子题目,叫“语义识别”。即便是这样,在今天有限的文章描述以及PPT演示,也难以涵盖语义识别这个领域的全部内容。

今天的文章以PPT为主线,受制于时间限制以及这个领域内容的确非常多非常深,即便是潜心钻严三年,是否能真正就说掌握了自然语言处理的语义分析,谁也不敢保证。进无止境。这恐怕也是科学的魅力。本文今天主要分为六个章节,第一章节先对自然语言处理进行简要介绍。主要对自然语言处理(Natural Language Processing, 下文会以NLP替代。)的苦命分类进行概要介绍。同时介绍一下NLP在文本和语音两个方面的商业应用。第二章节从发现历程、参与的公司以及行业规模,介绍当前NLP发展现状。第三章,对整个NLP体系进行梳理。第四、五、六章节主要对NLP中语义识别中的句法分析、话语分割、指代消解的基础原理进行讲述。
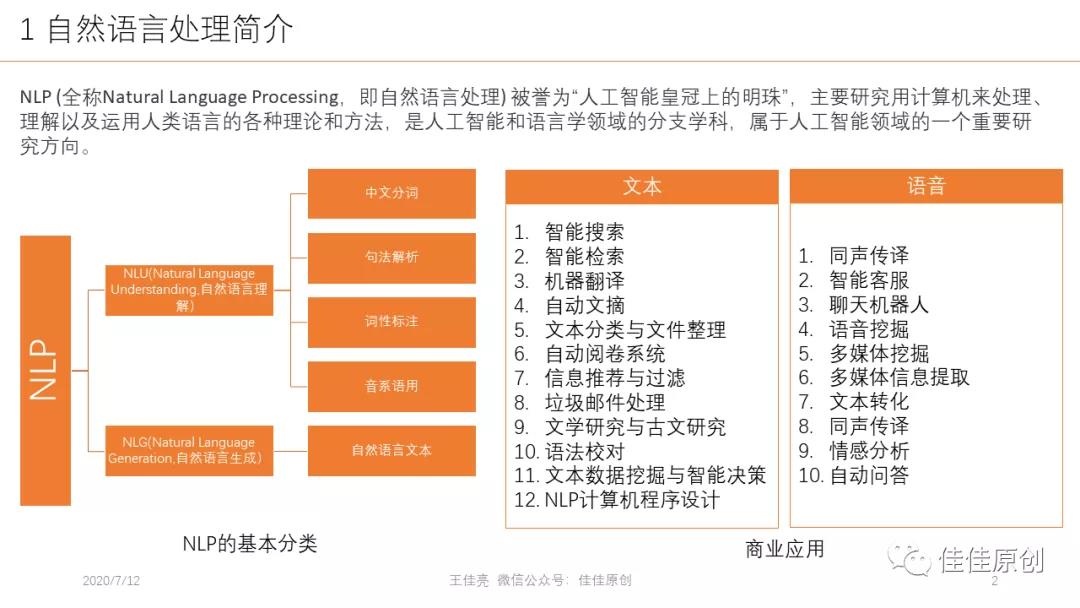
自然语言的理解层次,一般分为:语音分析、词法分析、句法分析、语义分析、语用分析。简单来讲,语音分析主要是根据音位规则,从语音流中提取出独立的音素,再根据音位形态规则找出音节及其所对应的单词;词法分析主要是找出词汇中的词素,从而获得其语音学的信息;句法分析,则是对句子和句子中的短语结构进行分析,发现其内存的关联关系;语义分析是要找出单词、结构,通过结合上下文,获得准确的含义;语用分析,则是研究语言所处在的实际语言环境中对语言使用者所产生的实际作用。

1950:图灵测试、经验语义方法、基于规则的方法。
1970:基于统计的方法、理性语义方法。2008年:深度学习。
2013年,Word Embeddings(Word2Vec),即将高维词向量嵌入到一个低维空间,Neural Networks for NLP(RNN LSTM CNN)。
2014年,Seq2Seq Models,Seq2Seq模型是输出的长度不确定时采用的模型;MachineTranslation, Structure Prediction。2015年,Attention,把一个输入序列表示为连续序列,解码生成一个输出序列,模型每一步都是自回归的,即假设之前生成的结果都是作为生成下一个符号的额外输入;Transformer,直接把一句话当做一个矩阵进行处理。
2018年,Memory-based Neural Network, NeuralTuringMachine。2018m, Pretrained Language Modes, ELMo,BERT。
2019年,Natural Language Generation,Reasoning, Bigger Models。
自然语言处理(NLP)正处于历史上最好的发展时期,技术在不断进步并与各个行业不断融合、落地。数据显示,我国NLP(自然语言处理)技术市场规模持续增长,2018年我国NLP(自然语言处理)技术市场规模达到了20.6亿元,同比增长52.6%。未来随着NLP技术不断进步,将具有大规模的市场需求和可扩展的巨大市场空间。预计2021年市场规模将达到近70亿元。
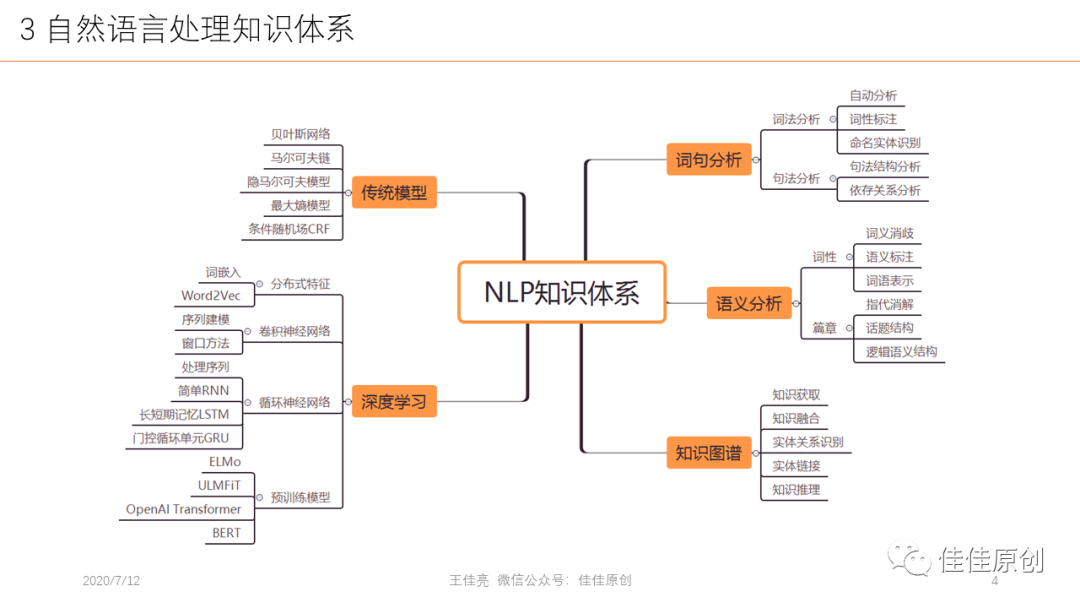
NLP整个知识体系非常多。研究模式主要是对自然语言场景问题,算法如何应用到解决这些问题。即便是涉及如此多的基础知识,目前NLP仍然面临着许多的问题,例如:场景的困难,语言的多样性、多变性、歧义性,使得NLP准确性受到制约。学习的困难,如何设计高效的学习模型?语料的困难,NLP应该使用什么样的语料?如何获得这些语料?

对于语义识别,需要对句法进行剖析,因此剖析在问答系统、信息抽取、语法检查中都起着非常重要的作用。1954年1月7日,美国乔治敦大学和IBM公司首先成功地将60多句俄语自动翻译成英语。当时的系统还非常简单,仅包含6个语法规则和250个词。而实验者声称:在三到五年之内就能够完全解决从一种语言到另一种语言的自动翻译问题。但直到今天,自然语言处理别说是自动翻译,简单的句法分析仍然有很多要完善的空间。“咬死了猎人的狗。”究竟是“[咬死了猎人][的狗]”还是“[咬死了][猎人的狗]”呢?如果不借助于上下文和语境,即便是人都很难理解,更不用说使用的句法分析了。

我们通过计算,可以增加句法分析的准确性。但是否能真实反应语义,仍然有很大的发展空间。

我们可以计算布朗预料库中每个句子的平均词数。在其他情况下,文本可能只是一个字符流。在将文本分词之前,需要将它分割成句子。有时可以借助于标点体符号以及一些典型的计算机符号,例如换行符来进行对句子分隔,但对于没有任何标点符号的文字段落来讲,人类可以借助经验理解里面的内容,NLP是否也能准备分割,也是比较难的一个研究领域,还有很大的发展空间。

指代消解是NLP里非常重要的一个细分的研究领域,应用场景非常多。例如智能对话预定酒店机票,“从天津到北京的机票多少钱?” 计算机NLP后,给出一个结果,这个时候,再问“那到上海呢?”,这个就需要NLP有更深层的理解了。而现实中的对话场景,远比这个要复杂的多,NLP是否能准确识别,就依赖于指代消解的准确度了。这直接关系到NLP的产品质量。
总结:
今天主要是对NLP中的语义识别的一个领域进行初步探索。人工智能是一个非常大的范畴,即便人工智能的子领域NLP,涉及的基础研究也非常多,而且这些基础研究短时间内也很难见效,很多公司都有业绩压力,往往出于收益,即便不是一个很完善的NLP产品,也先要推向市场。不论是NLP应用在哪个领域,构建什么样的产品,解决什么样的现实问题,根本还是要依赖于基础科技的研究,一个个丰富多彩的NLP产品,都是由一个个基础功能整合而成。正所谓,不积跬步无以至千里,不积小流无以成江海。